缓存常见问题及解决方式有哪些「缓存常见问题及解决方式」
缓存问题
产生原因
解决方案
缓存不一致
同步更新失败、异步更新
最终一致
缓存穿透
恶意攻击
空对象缓存、布隆过滤器
缓存击穿
热点key失效
互斥更新、随机退避、
缓存雪崩
缓存挂掉
快速失败熔断、
 缓存常见问题
缓存常见问题
由于引入缓存首先需要考虑的就是缓存更新的方式,之前在缓存更新的几种模式中我们介绍过。除了这个问题还有一些常见的问题,整理出一个表格,如下图所示:
缓存问题
产生原因
解决方案
缓存不一致
同步更新失败、异步更新
最终一致
缓存穿透
恶意攻击
空对象缓存、布隆过滤器
缓存击穿
热点key失效
互斥更新、随机退避、
缓存雪崩
缓存挂掉
快速失败熔断、主从模式、集群模式、差异失效时间
大key
存储value很大、集合数据过多、数据未清理
拆分key,清理key
热点key
预期外的访问量陡增,如突然出现的爆款商品
对key进行reHash然后复制到不同集群,使用读写分离架构
数据不一致一致性问题数据不一致的问题,可以说只要使用缓存,就要考虑如何面对这个问题。缓存不一致产生的原因一般有两方面:
选择缓存更新模式的不同造成的不一致,例如[缓存更新的几种模式]的Cache Aside不管是先更新db还是先删除或更新cache,在高并发的情况下都有可能造成不一致的情况,只是不同的更新方式造成不一致的概率不一样,尽可能的选择造成不一致概率最小的更新模式。系统问题导致失败造成的不一致,在这里就是如缓存服务的机器宕机,网络异常造成的更新失败等。解决方案采用强一致性协议,很少使用。最终一致性,在绝大部分场景中,特别是互联场景下,大多是保证最终一致性。 重试机制mq 更新数据库,若这一步就失败,更新事务失败回滚。 更新缓存失败,将失败的数据写入mq 消费mq得到失败的数据,重新删除缓存 订阅数据库binlog[参考MySQL复制原理及应用canal],解耦缓存更新过程。缓存穿透问题产生这个问题的原因可能是外部的恶意攻击,例如,对用户信息进行了缓存,但恶意攻击者使用不存在的用户id频繁请求接口,导致查询缓存不命中,然后穿透 DB 查询依然不命中。这时会有大量请求穿透缓存访问到 DB,增加数据库压力甚至导致系统宕机。
解决方案业务上做非法参数的校验,尽量避免非法请求打到缓存。对不存在的用户,在缓存中保存一个空对象进行标记,防止相同 ID 再次访问 DB。不过有时这个方法并不能很好解决问题,可能导致缓存中存储大量无用数据。使用 BloomFilter 过滤器,BloomFilter 的特点是存在性检测,如果 BloomFilter 中不存在,那么数据一定不存在;如果 BloomFilter 中存在,实际数据也有可能会不存在。非常适合解决这类的问题。布隆过滤器下面简单介绍下布隆过滤器,布隆过滤器内部维护一个bitArray(位数组), 开始所有数据全部置 0 。当一个元素过来时,能过多个哈希函数(hash1,hash2,hash3…)计算不同的在哈希值,并通过哈希值找到对应的bitArray下标处,将里面的值 0 置为 1 。需要说明的是,布隆过滤器有一个误判率的概念,误判率越低,则数组越长,所占空间越大。误判率越高则数组越小,所占的空间越小。
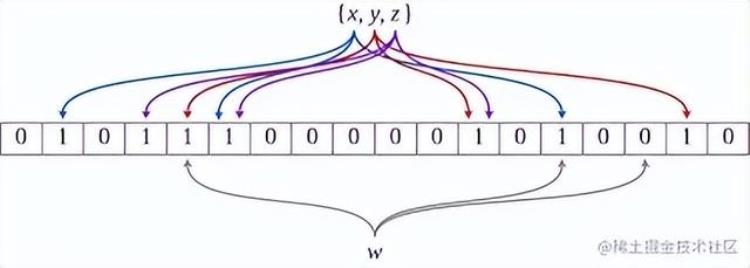
以上图为例,具体的写入过程(如有3个hash函数): 假设集合里面有3个元素{x, y, z},哈希函数的个数为3。首先将位数组进行初始化,将里面每个位都设置为0。对于集合里面的每一个元素,将元素依次通过3个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为1。
查询a元素是否存在集合中的时候,同样的方法将a通过哈希映射到位数组上的3个点。如果3个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。反之,如果3个点都为1,则该元素可能存在集合中。
注意:此处不能判断该元素是否一定存在集合中,可能存在一定的误判率。可以从图中可以看到:假设某个元素通过映射对应下标为4,5,6这3个点。虽然这3个点都为1,但是很明显这3个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是1,这是误判率存在的原因。
布隆过滤器能确定一个值一定不存在,但是不能确定一个值一定存在。缓存穿透正好利用"布隆过滤器能确定一个值一定不存在",因此不存在计算误差。
使用布隆过滤器解决缓存穿透了解布隆过滤器原理后,我们用布隆过滤器解决缓存穿透问题就很简单了,在缓存前加一层布隆过滤器,利用布隆过滤器bitset存储结构存储数据库中所有值,查询缓存前,先查询布隆过滤器,若一定不存在就返回。
方案对比:
方案
使用场景
使用成本
缓存空对象
1. 空数据量不大 2. 数据频繁变化实时性高
1.代码维护简单 2.需要过多的缓存空间 3. 数据不一致
过滤器
1.数据量比较大 2. 数据命中不高 3. 数据相对固定实时性低
1.代码维护复杂 2.缓存空间占用少
缓存击穿问题缓存击穿,就是某个热点数据失效时,很多请求这一时间都查不到缓存,然后全部请求并发打到了数据库去查询数据构建缓存,造成数据库压力非常大甚至宕机。
解决方案解决这个问题有如下办法:
使用互斥锁更新,保证同一个进程中针对同一个数据不会并发请求到 DB,减小 DB 压力。java复制代码 public Object getCache(final String key) { Object value = Redis.get(key); //缓存值过期 if (value == null) { //加mutexKey的互斥锁 String mutexKey = mutexKey(key); if (redis.setnx(mutexKey, 1, time)) { value = db.get(key); redis.set(key, value, time); redis.delete(mutexKey); } else { sleep(100); return get(key); } } return value;}不给热点数据设置过期时间,由后台异步更新缓存,或者在热点数据准备要过期前,提前通知后台线程更新缓存以及重新设置过期时间;方法
优点
缺点
互斥锁
1.简单易用2.一致性保证
1.存在线程阻塞的风险2.数据库访问的压力转到分布式锁上来
异步更新
1.相比互斥锁方案,降低线程阻塞的时间
1.代码更复杂2.逻辑过期时间会占用一定的内存空间
缓存雪崩问题缓存雪崩。产生的原因是:
大量请求同时打到DB上,比如大量key同时过期缓存服务挂掉,这时所有的请求都会穿透到 DB。解决方案使用快速失败的熔断限流策略,减少 DB 瞬间压力;使用主从模式和集群模式来尽量保证缓存服务的高可用。针对多个热点 key 同时失效的问题,可以在缓存时使用固定时间加上一个小的随机数,避免大量热点 key 同一时刻失效。大key及热点key问题大key及热点key的定义(不同公司根据实际情况定义不同):
名词
解释
大Key
通常以Key的大小和Key中成员的数量来综合判定,例如:1. Key本身的数据量过大:一个String类型的Key,它的值为5 MB。2. Key中的成员数过多:一个ZSET类型的Key,它的成员数量为10,000个。3. Key中成员的数据量过大:一个hash类型的Key,它的成员数量虽然只有1,000个但这些成员的Value(值)总大小为100 MB。
热Key
通常以其接收到的Key被请求频率来判定,例如:1. QPS集中在特定的Key:Redis实例的总QPS(每秒查询率)为10,000,而其中一个Key的每秒访问量达到了7,000。2. 带宽使用率集中在特定的Key:对一个拥有上千个成员且总大小为1 MB的HASH Key每秒发送大量的HGETALL操作请求。3. CPU使用时间占比集中在特定的Key:对一个拥有数万个成员的Key(ZSET类型)每秒发送大量的ZRANGE操作请求。
大key及热点key的问题:
类别
说明
大Key
1. 客户端执行命令的时长变慢。2. Redis内存达到maxmemory参数定义的上限引发操作阻塞或重要的Key被逐出,甚至引发内存溢出(Out Of Memory)。3. 集群架构下,某个数据分片的内存使用率远超其他数据分片,无法使数据分片的内存资源达到均衡。4. 对大Key执行读请求,会使Redis实例的带宽使用率被占满,导致自身服务变慢,同时易波及相关的服务。5. 对大Key执行删除操作,易造成主库较长时间的阻塞,进而可能引发同步中断或主从切换。
热点Key
1. 占用大量的CPU资源,影响其他请求并导致整体性能降低。2. 集群架构下,产生访问倾斜,即某个数据分片被大量访问,而其他数据分片处于空闲状态,可能引起该数据分片的连接数被耗尽,新的连接建立请求被拒绝等问题。3. 在抢购或秒杀场景下,可能因商品对应库存Key的请求量过大,超出Redis处理能力造成超卖。4. 热Key的请求压力数量超出Redis的承受能力易造成缓存击穿,即大量请求将被直接指向后端的存储层,导致存储访问量激增甚至宕机,从而影响其他业务。
解决方案大key单key存储value很大可以把value对象拆成多份,使用multiGet,这样做的意义在于减少操作在一个节点的压力,分散到多个节点。使用hash,每个filed存储对象的各属性。集合存储了过多的的值将这些元素分拆。以hash为例,原先的正常存取流程是scss复制代码hget(hashKey, field); hset(hashKey, field, value);现在,固定一个桶的数量,比如 1000, 每次存取的时候,先本地进行rehash,确定了该field落在哪个key上。ini复制代码newHashKey = hashKey ( *hash*(field) % 1000); hset (newHashKey, field, value) ; hget(newHashKey, field);定期删除过期大key热点key在Redis集群架构中对热Key进行复制在Redis集群架构中,由于热Key的迁移粒度问题,无法将请求分散至其他数据分片,导致单个数据分片的压力无法下降。此时,可以将对应热Key进行rehash后复制并迁移至其他数据分片,例如将热Key foo复制出3个内容完全一样的Key并名为foo2、foo3、foo4,将这三个Key迁移到其他数据分片来解决单个数据分片的热Key压力。该方案的缺点在于需要联动修改代码,同时带来了数据一致性的挑战(由原来更新一个Key演变为需要更新多个Key),仅建议该方案用来解决临时棘手的问题。使用读写分离架构如果热Key的产生来自于读请求,您可以将实例改造成读写分离架构来降低每个数据分片的读请求压力,甚至可以不断地增加从节点。但是读写分离架构在增加业务代码复杂度的同时,也会增加Redis集群架构复杂度。不仅要为多个从节点提供转发层(如Proxy,LVS等)来实现负载均衡,还要考虑从节点数量显著增加后带来故障率增加的问题。Redis集群架构变更会为监控、运维、故障处理带来了更大的挑战。
涓绘澘涓缂撳瓨鐨勫父瑙侀棶棰
銆銆缂撳瓨鏄鎸囦复鏃舵枃浠朵氦鎹㈠甫搴嗗尯锛屽彲浠ュ垎涓轰竴绾х紦瀛橈紝浜岀骇缂撳瓨锛孋PU缂撳瓨銆傜紦瀛樺瓨鍦ㄧ殑浣嶇疆涓鑸鏄涓绘澘銆備富鏉挎槸鐢佃剳绯荤粺鐨勯噸瑕佺粍鎴愰儴鍒嗭紝鍙堟槸鏁呴殰娑夊強闈㈡渶澶氱殑閰嶄欢銆備富鏉夸腑鐨勭紦瀛樿姱鐗囬氬父涔熶細鍑虹幇鍚勭嶆晠闅滐紝浠ヤ笅浠嬬粛鍑犵嶅父瑙侀棶棰樼殑瑙e喅鏂规硶锛
銆 銆1.楂橀熺紦瀛樿姱鐗囦笉绋冲畾
銆銆濡傛灉鍦–OMS璁剧疆涓濡傛灉鍏佽告澘涓婁簩绾ч珮閫熺紦瀛(L2Cache鎴朎xternal Cache)锛岃繍琛岃蒋浠舵椂灏卞规槗姝绘満锛岃岀佹浜岀骇楂橀熺紦瀛樼郴缁熷氨鍙浠ユe父杩愯岋紝浣嗛熷害姣斿悓妗g數鑴戣佹參涓嶅皯銆 杩欐槸鍥犱负浣跨敤浜岀骇楂橀熺紦瀛樻椂鎵嶆墦寮璇ラ夐」鐨勫紑鍏筹紝鑰屼箣鍚庡氨鏈夋绘満鐜拌薄棰戠箒鍙戠敓锛屽洜姝ゆ柇瀹氫簩绾ч珮閫熺紦瀛樿姱鐗囧伐浣滀笉绋冲畾銆傚彲浠ョ敤鎵嬮愪釜鎰熻変富鏉夸笂鐨'浜岀骇楂橀熺紦瀛樿姱鐗囩殑娓╁害锛屽傛灉鏄庢樉鍦拌夊療鍒版湁涓涓鑺鐗囨瘮鍏跺畠鐨勭儹锛屽垯灏嗗叾鏇存崲鍚庣郴缁熸e父銆
銆 銆2.浜岀骇楂橀熺紦瀛樻崯鍧
銆銆濡傛灉鐢佃剳寮鏈鸿嚜妫杩囩▼涓鏂鍦ㄦ樉绀512K Cache鐨勫湴鏂广傛棦鐒跺湪鏄剧ず缂撳瓨澶勬绘満锛屽繀鐒舵槸璇ラ儴鍒嗘垨鍏跺悗鐨勯儴鍒嗘湁闂棰樸傚洜姝わ紝鍖哄垎寮楂橀熺紦瀛樺拰纭鐩樻晠闅滃氨鍙浠ヤ簡銆傚傛灉纭鐩樻槸濂界殑锛屽垯闂棰橀泦涓鍒颁簡楂橀熺紦瀛樹笂銆傚傛灉杩涘叆CMOS璁剧疆锛岀佹L2 Cache锛岀數鑴戞暚鐫佸氨鍙浠ユe父宸ヤ綔锛岃繖纭瀹氫负浜岀骇缂撳瓨鐨勯棶棰橈紝涓鑸楂橀熺紦瀛樿姱鐗囨槸鐒婂湪涓绘澘涓婄殑锛岃屼笖绠¤剼姣旇緝缁嗭紝鐢ㄦ埛鎵嬪姩鏇存崲姣旇緝楹荤儲锛屽洜姝ゅ彲浜琛屽瞾浠ラ佸幓缁翠慨閮ㄩ棬鎴栬呮洿鎹涓绘澘銆

文章评论