测试常用sql语句面试题「软件测试面试被问这些SQL语句不会怎么办于是推出这套SQL教程」
为什么呢?
Kitty小编告诉你:首先,从软件的三层架构谈起,大家都知道现在的软件基本要么是C/S架构,要么是B/S架构,但无论是C/S架构还是B/S架构最终都离不开DBS也就是数据库服务器。
数据库服务器是用来干什么的呢?存储前端用户填写的数据通过web服务器通过接口传递给后端保存在DBS数据库的表中,为了更好的保障软件产品的质量,作为测试人员不仅要学会发现前端的问题还要对DBS表中的业务数据进行检验,因为有时候由于网络等其它原
作为一名软件测试人员,学习SQL语句是必备。
为什么呢?
Kitty小编告诉你:首先,从软件的三层架构谈起,大家都知道现在的软件基本要么是C/S架构,要么是B/S架构,但无论是C/S架构还是B/S架构最终都离不开DBS也就是数据库服务器。

数据库服务器是用来干什么的呢?存储前端用户填写的数据通过web服务器通过接口传递给后端保存在DBS数据库的表中,为了更好的保障软件产品的质量,作为测试人员不仅要学会发现前端的问题还要对DBS表中的业务数据进行检验,因为有时候由于网络等其它原因在前端提前的数据生成结果与后端可能不致,这样就会造成后端产生大量bug。
例如:这里例举一个电商网站最容易出现的bug,有时候在网络较慢的情况下,用户并发数量较大,如果存在批量用户下单,在前端提前一条交易订单有时候网络较慢用户提交一次表单按钮无响应,可能还需要点击提交一次,这时候对于用户来说并不知道在数据库后端是否会生成两条数据的bug,但是我们作为一名质量保障人员是必须要去验证的,这时候我们难免会使用到数据库。

当然学会SQL语句除了用来检验数据,更重要的是生成测试数据,为什么要使用SQL来生成数据呢?使用Excel不行吗?
Excel用来生成参数化数据当然可行,但是大家应该知道Excel能够支持最大的数据量是65536行,超过这个数是不能支持的,作为大型互联网公司的一员,要想实现并发性能测试,基本上数据都是上亿的,在这种情况下仅仅依靠Excel来生成数据并不能满足日常的性能测试业务需求,这时候我们就需要使用SQL语句来帮助我们解决这个问题。

SQL语句对于一些小白学生来说难度有点大,但实际上你通过这篇超详细的文章教程学习,相信会让你大开眼界,费话少说直接上干货。
题目一:给你一张班级表,名称为:classes,如何创建表?表演内容如下图所示:

创建表的SQL语句如下:

注意:创建表成功后,查看一下此数据库下是否存在classes这个表,可能刚创建完成需要进行刷新才能立即看到数据结果。
题目二:如何给classes插入数据?SQL语句如下图所示:
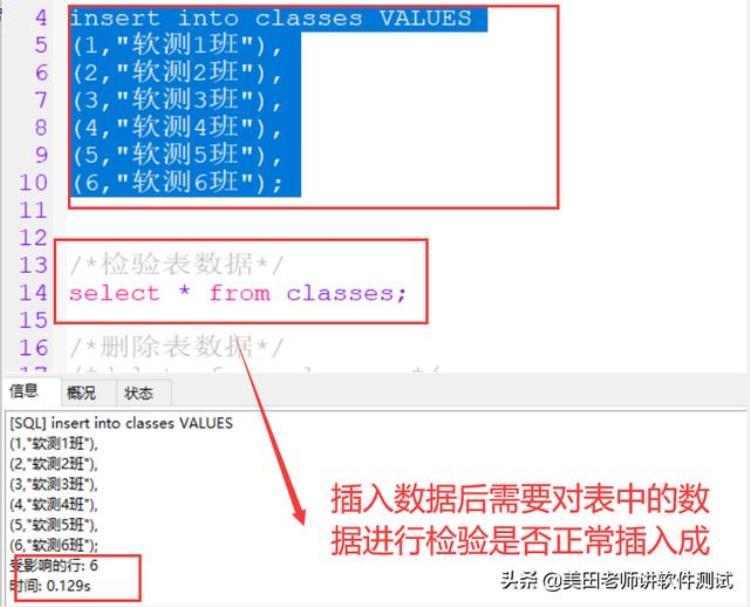
题目三:如何给classes name 字段改为为Name?SQL语句如下图所示:

注意:修改完成后使用select * from classes查询一下,看字段名是否变成了Name,发生改变表明修改字段名成功。
日常工作中除了学习制造数据,更重要的是需要对于多个表的数据进行关联,笔者也提供了以下资料供大家学习。
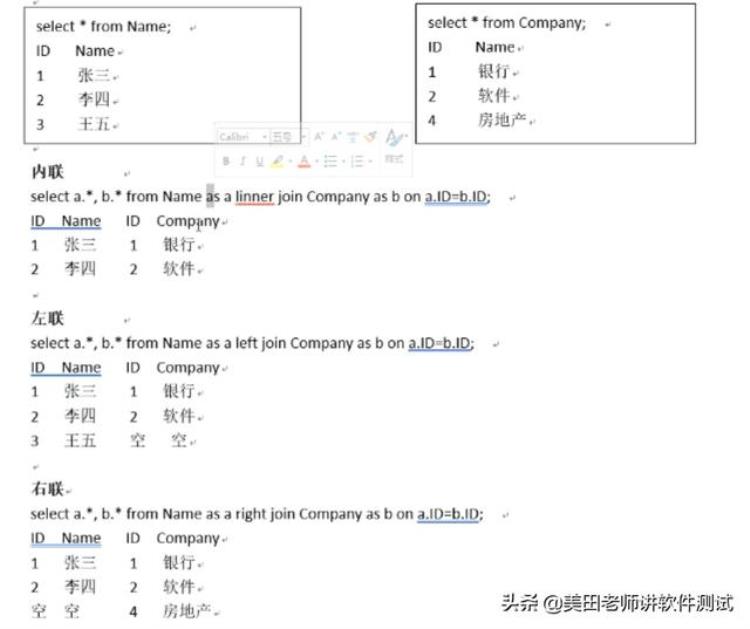
总结:学习SQL数据库真的没有大家想象的那么难,只要脚踏实地从0开始放平心态,按照老师讲的思路去理解SQL语句的原理及用途,其实很简单,希望能够帮助大家入门,今天的分享到此结束。

当面试官问你你有任何的sql的经验的时候我该怎么回答。我之前上过这个课
这兄和贺个基本都是问项目经验,你就编一个项目,说一个类似的写sql的经验就可以。从什么表抽数或怎么抽数的,怎么运算的,然后怎么得到结果的,不过说的时候可以有所保留,实羡派在说不明白的地方就说是上家公司的一些特定的人做的。这个一般讲课的时候老师会讲一两个只要记住就可以了。当然别把棚棚自己绕进去,因为如果真的没做过,而面试官还比较了解,那么很容易看出来的。当然前提是会写sql语句,知道基本写法,而且至少要了解部分常用函数,分组,排序,子查询,以及表关联方式,如果这些都不知道,那么还是不要说比较好,容易漏。
软件测试SQL面试题
数据库,无外乎增删改查:增:
insert into A表 values (value1,value2,value3......)向A表中新增数据
删:
delete from A表 ( where id=1) 删除A表(删除A表id=1的数据)如果删除某个测试数据,记得加where条件,否则整张表的数据都被删除,防止误操作!不过,数据可以回滚找回。
truncate A表:清除表数据,耐胡数据无法回滚。
drop A表:整表结构删除,即,这张表不存在了。
改:
update A表 set name=test where id=1 修改id为1的name值为test
查:
1:左关联和右关联的区别?
答:左关联( left join )左表为主,左表数据全部显示,右表显示关联数据,无关联显示null,右关联( right join )相反。
2:模糊查询?
select * from A表 where name like %a% (name包含a字母)
查询结果: a , a bc,b a c,bc a
select * from A表 where name like 昌手拦 a% (name值以a字母开头)
查询结果: a , a bc
select * from A表 where name like %a (name值以a字母结尾)
查询结果: a ,bc a
3:统计:count和sum
count统计表的 记录数 ,sum统计某列数值 总和 。
select count(*) from A表
select count(1) from A表
select count(列名) from A表
区别:
count( * ): 所有记录薯哪,包括null值
count( 1 ):所有记录,包括null值
count( 列名 ):列名有值得记录, 不包括null值
执行效率:
以前是count(1)比count(*)快,但现在count(*)底层算法优化,查询更快,所以推荐count(*)
统计有效数据的记录,count(列名)
select sum(列名) from A表 计算列名数值总和。
举例:
查询A表中,姓王的用户量
select count(*) from A where name like 王%
Plus版
1:去重distinct,查询不重复记录的数据
必须放开头
select distinct 列名 from 表名(查询所有列名数据,去掉重复数据)
举例:
表A,查询考核等级grade,有哪些值
select distinct grade from A
2:分组group by,根据某个字段分组
select 列名 from 表名 group by 列名,一般会配合聚合函数一起使用
举例:
表A中,查询考核等级grade字段,不同值各多少人
select grade,count(*) from A group by grade
3:limit,查询结果返回的数量,多用于分页查询
select * from 表名 limit i,n i代表查询结果的索引值,默认从0开始,n返回查询的结果数。
举例:
订单表A,查询第21条到30条数据
select * from A limit 20,10
可能会问为什么不能直接用id查询?因为id不准确,可能存在id不连续的情况。如果某条数据被物理删除了呢?
何为物理删除和逻辑删除?
物理 删除 ,直接将某条数据,从表中删除。
逻辑 删除,仅通过某个字段标记删除,实际表中还存在。(比如:is_delete=1代表已删除,is_delete=0未删除)
4:排序order by 列名 asc(列名值升序排列)和order by 列名 desc(列名值降序排列)
举例:
用户表A,按照用户id升序(select查询默认根据主键升序,所以升序,不加order by也可以)
select * from A order by id asc同select *from A
用户表A,按照新建时间倒序
select * from A order by create_time desc
5:in和between查询某个范围的数值
举例:
in:查询指定数值的数据
between:查询某个范围内的数据
举例:
查询表A中,id=1和id=10的数据
select * from A where id in(1,10)
查询表A中,1月份新增的数据
select * from A where create_time between 2022-01-01 and 2022-01-31 23:59:59
已知有如下4张表:
学生表:student(学号,学生姓名,出生年月,性别)
成绩表:score(学号,课程号,成绩)
课程表:course(课程号,课程名称,教师号)
教师表:teacher(教师号,教师姓名)
准备练习数据
1)创建学生表(student)
2)创建成绩表(score)
3)创建课程表(course)
4)教师表(teacher)
1)学生表添加数据
2)成绩表添加数据
3)课程表添加数据
4)教师表添加数据
简单查询
查询姓“猴”的学生名单
查询姓名中最后一个字是“猴”字的学生名单
查询姓名中带“猴”字的学生名单
查询姓“孟”老师的个数
汇总分析
1.汇总分析
查询课程编号为“0002”的总成绩
查询选了课程的学生人数
2.分组
查询各科成绩的最高分和最低分, 以如下的形式显示:课程号,最高分,最低分
查询每门课程选修的学生数
3.分组结果的条件
查询至少选修两门课程的学生学号
查询同名同姓学生名单并统计同名人数
分析:条件:怎么算姓名相同?按姓名分组后人数大于等于2,因为同名的人数大于等于2,分析出这一点很重要
查询不及格的课程并按课程号从大到小排列
查询每门课程的平均成绩,结果按平均成绩升序排序,平均成绩相同时,按课程号降序排列
检索课程编号为“0004”且分数小于60的学生学号,结果按按分数降序排列
统计每门课程的学生选修人数(超过2人的课程才统计),要求输出课程号和选修人数,查询结果按人数降序排序,若人数相同,按课程号升序排序
查询两门以上不及格课程的同学的学号及其平均成绩
第2步:再加上限制条件:
1)不及格课程
2)两门以上[不及格课程]
4.查询结构排序,分组的指定条件
查询学生的总成绩并进行排名
查询平均成绩大于60分的学生的学号和平均成绩
复杂查询
查询课程成绩小于60分学生的学号、姓名
【知识点】子查询
1.翻译成大白话
1)查询结果:学生学号,姓名
2)查询条件:所有课程成绩 < 60 的学生,需要从成绩表里查找,用到子查询
第1步,写子查询(所有课程成绩 < 60 的学生)
第2步,查询结果:学生学号,姓名,条件是前面1步查到的学号
查询没有学全所有课的学生的学号、姓名
查询出只选修了两门课程的全部学生的学号和姓名
查找1990年出生的学生名单
查询本月过生日的学生
工作中会经常遇到这样的业务问题:
如何找到每个类别下用户最喜欢的产品是哪个?
如果找到每个类别下用户点击最多的5个商品是什么?
这类问题其实就是常见的:分组取每组最大值、最小值,每组最大的N条(top N)记录。
分组取每组最大值,按课程号分组取成绩最大值所在行的数据
分组取每组最小值,按课程号分组取成绩最小值所在行的数据
每组最大的N条记录,查询各科成绩前两名的记录
第1步,查出有哪些组
我们可以按课程号分组,查询出有哪些组,对应这个问题里就是有哪些课程号
第2步:先使用order by子句按成绩降序排序(desc),然后使用limt子句返回topN(对应这个问题返回的成绩前两名)
第3步,使用union all 将每组选出的数据合并到一起
多表查询
查询所有学生的学号、姓名、选课数、总成绩
查询平均成绩大于85的所有学生的学号、姓名和平均成绩
查询学生的选课情况:学号,姓名,课程号,课程名称
文章评论